Most PM2.5 Polluted City in Mexico - 2018
Diego Valle-Jones
2020-11-04
Source:vignettes/articles/pm25_awards.Rmd
pm25_awards.RmdWe can use rsinaica to find out which city is the most PM25-polluted in all of Mexico.
First, we load the packages:
## Auto-install required R packages
packs <- c("dplyr", "ggplot2", "gghighlight", "lubridate", "anomalize",
"aire.zmvm", "tidyr", "zoo", "plotly", "rsinaica")
success <- suppressWarnings(sapply(packs, require, character.only = TRUE))
if (length(names(success)[!success])) {
install.packages(names(success)[!success])
sapply(names(success)[!success], require, character.only = TRUE)
}Download
Then we download the data for the whole year of 2018 using the sinaica_param_data function. Since the maximum data range we can download is 1 month, we have to use a little mapply magic to download the entire year.
# Download all PM25 pollution data in 2018
pm25_2018 <- bind_rows(
mapply(sinaica_param_data,
"PM2.5",
seq(as.Date("2018-01-01"), as.Date("2018-12-01"), by = "month"),
seq(as.Date("2018-02-01"), as.Date("2019-01-01"), by = "month") - 1,
SIMPLIFY = FALSE)
)
I thought there would be a few cities that collected PM25 data manually (they collect it through a filter and send it to be weighted to an external lab, sometimes in another country). But no air quality station collected manual PM2.5 in 2018.
bind_rows(
mapply(sinaica_param_data,
"PM2.5",
seq(as.Date("2018-01-01"), as.Date("2018-12-01"), by = "month"),
seq(as.Date("2018-02-01"), as.Date("2019-01-01"), by = "month") - 1,
"Manual",
SIMPLIFY = FALSE)
)
#> [1] id station_id station_name station_code
#> [5] network_name network_code network_id date
#> [9] hour parameter value_actual valid_actual
#> [13] validation_level unit value
#> <0 rows> (or 0-length row.names)This is what the data looks like:
| id | station_id | station_name | station_code | network_name | network_code | network_id | date | hour | parameter | value_original | flag_original | valid_original | value_actual | valid_actual | date_validated | validation_level | unit | value |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 102PM2.518010100 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 0 | PM2.5 | 85.223 | 130 | 1 | 85.223 | 1 | NA | 0 | µg/m³ | 85.223 |
| 102PM2.518010101 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 1 | PM2.5 | 83.011 | 130 | 1 | 83.011 | 1 | NA | 0 | µg/m³ | 83.011 |
| 102PM2.518010102 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 2 | PM2.5 | 110.22 | 130 | 1 | 110.22 | 1 | NA | 0 | µg/m³ | 110.220 |
| 102PM2.518010103 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 3 | PM2.5 | 132.92 | 130 | 1 | 132.92 | 1 | NA | 0 | µg/m³ | 132.920 |
| 102PM2.518010104 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 4 | PM2.5 | 133.82 | 130 | 1 | 133.82 | 1 | NA | 0 | µg/m³ | 133.820 |
| 102PM2.518010105 | 102 | Centro | CEN | Guadalajara | GDL | 63 | 2018-01-01 | 5 | PM2.5 | 107.7 | 130 | 1 | 107.7 | 1 | NA | 0 | µg/m³ | 107.700 |
Cleanup
Once we’ve downloaded the data we filter values below 1 µg/m³ since they’re probably calibration errors. And we only include stations that reported for more than 80% of days (292). We also have to take into account that PM25 data is measured as a 24 hour average.
# pm25_2018[which(pm25_2018$value_actual != pm25_2018$value_original),]
# pm25_2018[which(!is.na(pm25_2018$date_validated)),]
## filter stations that didn't report at least 47 weeks of the year
df_filtered <- pm25_2018 %>%
#filter(value < 250) %>%
mutate(value = if_else(value < 1, NA_real_, value)) %>%
group_by(network_name) %>%
filter(!is.na(value)) %>%
mutate(nweeks = n_distinct(week(date))) %>%
filter(nweeks >= 47) %>%
select(-nweeks) %>%
ungroup()
df_max <- df_filtered %>%
complete(station_id,
hour = 0:23,
date = as.character(seq(as.Date("2018-01-01"), as.Date("2018-12-31"), by = "day"))) %>%
group_by(station_id, network_name) %>%
arrange(station_id, date, hour) %>%
mutate(roll24 = rollapply(value, 24, mean, na.rm = TRUE, partial = 18,
fill = NA, align = "right")) %>%
ungroup() %>%
#summarise(mean = mean(value, na.rm = TRUE)) %>%
group_by(date, network_name) %>%
summarise(max = max(roll24, na.rm = TRUE)) %>%
ungroup() %>%
add_count(network_name) %>%
## Only include stations that reported for more than 80% of days (292)
filter(n >= (365*.8)) %>%
select(-n) %>%
filter(is.finite(max)) %>%
arrange(date)
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> Warning in max(roll24, na.rm = TRUE): no non-missing arguments to max; returning
#> -Inf
#> `summarise()` regrouping output by 'date' (override with `.groups` argument)When plotting the daily 24 hour average maximums we can see that there are still some obvious errors in the data.
ggplot(df_max, aes(as.Date(date), max)) +
geom_line(size = .3, color = "black") +
facet_wrap(~ network_name, ncol = 3) +
ggtitle(expression(paste("Maximum daily ", PM[2.5], " concentration by network"))) +
xlab("date") +
ylab(expression(paste("daily maximum 24 average of ", PM[2.5],
" (", mu,"g/", m^3, ")"))) +
theme_bw() +
theme(axis.text.x=element_text(angle=60,hjust=1))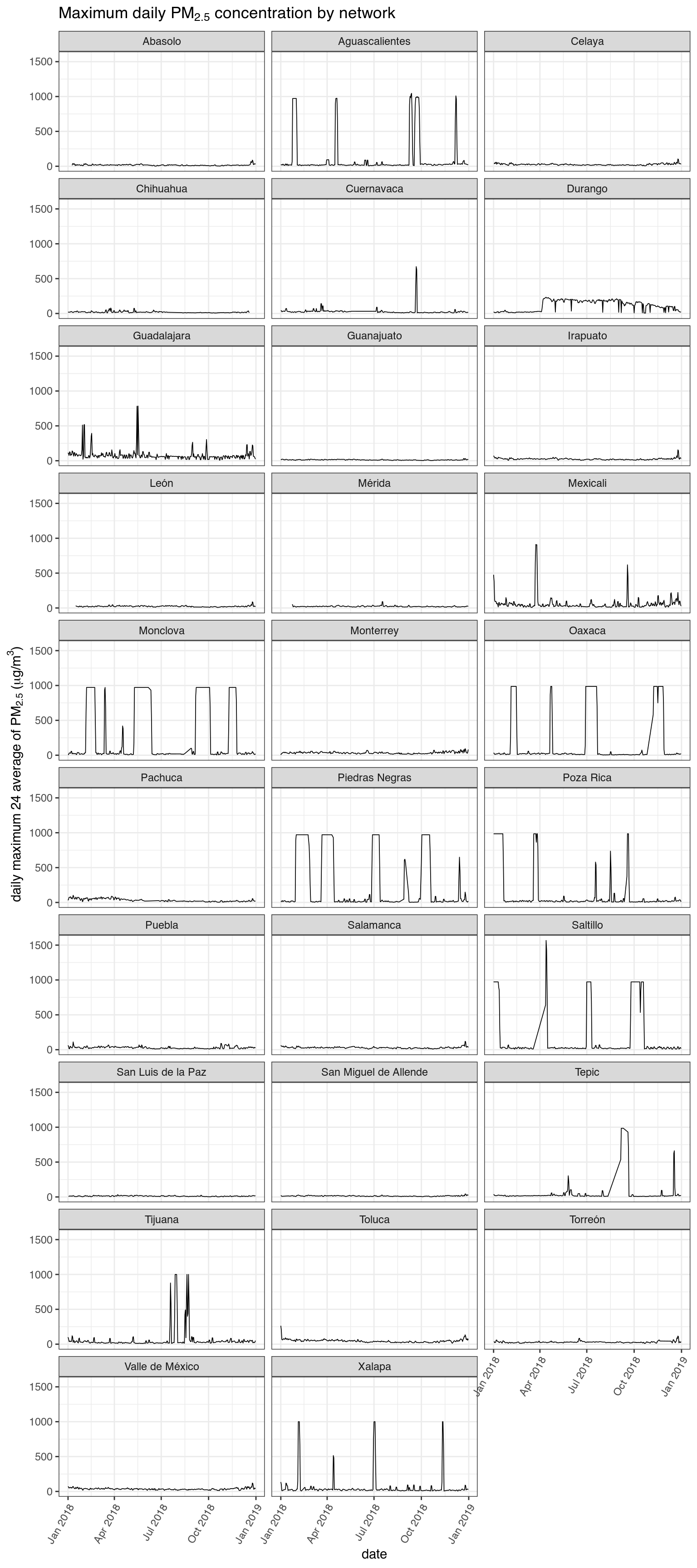
It looks like we can safely remove values above 200 µg/m³ and get rid of the Aguascalientes, Irapuato and Monclova networks.
Anomalies
We can also use the anomalize package to detect extreme values, but actually figuring out if they are errors is a little bit more tricky since fires can temporarily spike PM25 levels as often happens during the winter holidays when people burn trash and tires, and set off fireworks. I’ve opted not to remove them, because of the spikes around new year. Since I’m interested in the average of the whole year, these PM25 outliers are unlikely to have a substantial effect on the rankings.
df_max <- filter(df_max, !network_name %in%
c("Irapuato", "Monclova", "Aguascalientes")) %>%
filter(max <= 200)
df_max <- df_max %>%
ungroup() %>%
group_by(network_name) %>%
mutate(date = as.Date(date)) %>%
time_decompose(max, method = "stl") %>%
anomalize(remainder, method = "iqr", alpha = 0.01) %>%
time_recompose()
#> Registered S3 method overwritten by 'quantmod':
#> method from
#> as.zoo.data.frame zoo
# Anomaly Visualization
df_max %>% plot_anomalies(time_recomposed = TRUE, ncol = 3, alpha_dots = 0.25) +
labs(title = "Tidyverse Anomalies", subtitle = "STL + GESD Methods") 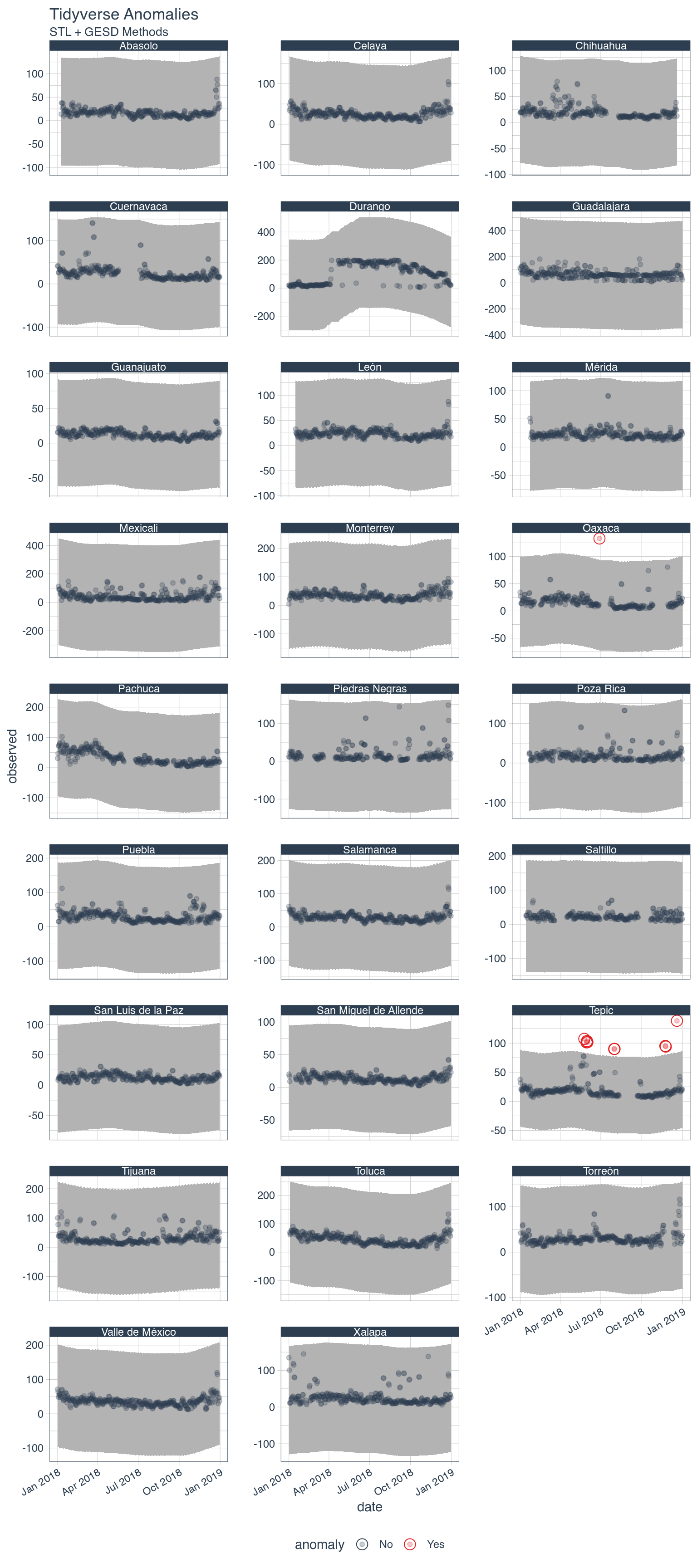
## Don not remove outliers, if you look at the chart some values around new year
## are detected as spikes, but it's people setting off fireworks and burning trash
## df_max <- filter(df_max, anomaly != "Yes")It was decided to remove Irapuato from the rankings and keep Tepic because PM2.5 values can spike because of fires. Normally I would have removed Mexicali since it didn’t report any correct data during the winter season, but its levels of PM2.5 where so high that I decided to keep it.
Most PM25-Polluted City
And here is the most PM25-polluted city in Mexico: Toluca
ggplot(df_max, aes(as.Date(date), observed,
group = network_name, color = network_name)) +
gghighlight(mean(observed, na.rm = TRUE), max_highlight = 1L) +
theme_bw() +
ggtitle(expression(paste("Pollution measuring network with the highest ",
PM[2.5], " pollution values in 2018")),
subtitle = "Based on the mean of the highest 24-hour rolling average daily maximums. Source: SINAICA") +
xlab("date") +
ylab(expression(paste(PM[2.5], " ", mu,"g/", m^3)))
#> Warning: Tried to calculate with group_by(), but the calculation failed.
#> Falling back to ungrouped filter operation...
Top polluted cities
knitr::kable(
df_max %>%
group_by(network_name) %>%
summarise(mean = mean(observed, na.rm = TRUE)) %>%
arrange(-mean) %>%
head(10)
)
#> `summarise()` ungrouping output (override with `.groups` argument)| network_name | mean |
|---|---|
| Durango | 106.18640 |
| Guadalajara | 65.08059 |
| Toluca | 44.71798 |
| Mexicali | 43.50160 |
| Valle de México | 35.69489 |
| Monterrey | 35.10889 |
| Pachuca | 33.47532 |
| Tijuana | 31.75722 |
| Puebla | 29.66793 |
| Torreón | 29.54238 |
The top 3 most PM25-polluted cities in Mexico. Note that Mexicali didn’t report any data during the winter, which is the season with the highest levels of PM2.5 pollution, it could probably have ranked higher if they bothered to keep their instruments working.
top3 <- filter(df_max, network_name %in% c("Toluca",
"Cuernavaca",
"Guadalajara"))[, 1:3]
top3 <- spread(top3, network_name, observed)
top3$date <- as.Date(as.Date(top3$date))
#top3$Toluca <- na.spline(top3$Toluca)
#top3$Guadalajara <- na.spline(top3$Guadalajara)
#top3$Mexicali <- na.spline(top3$Mexicali)
x <- list(
title = "date"
)
y <- list(
title = "daily maximum 24 average of PM2.5"
)
plot_ly(as.data.frame(top3), x = ~date, y = ~`Toluca`, name = "Toluca" ,
type = 'scatter', mode = 'lines', line = list(color = '#e41a1c'), width = .5) %>%
add_trace(y = ~Guadalajara, name = 'Guadalajara', mode = 'lines', line = list(color = '#377eb8'), width = .5) %>%
add_trace(y = ~Cuernavaca, name = 'Cuernavaca', mode = 'lines', line = list(color = '#4daf4a'), width = .5) %>%
layout(title = "Top 3 most PM2.5-polluted cities in Mexico", xaxis = x, yaxis = y)Days with bad air quality
Number of days with bad air quality (Índice IMECA MALO)
df_max %>%
group_by(network_name) %>%
filter(observed > 45.05) %>%
summarise(count = n()) %>%
arrange(-count) %>%
head() %>%
knitr::kable()
#> `summarise()` ungrouping output (override with `.groups` argument)| network_name | count |
|---|---|
| Guadalajara | 276 |
| Durango | 210 |
| Toluca | 172 |
| Mexicali | 127 |
| Pachuca | 99 |
| Tijuana | 60 |
Number of days with very bad air quality (Índice IMECA MUY MALO).
df_max %>%
group_by(network_name) %>%
filter(observed > 97.45) %>%
summarise(count = n()) %>%
arrange(-count) %>%
head() %>%
knitr::kable()
#> `summarise()` ungrouping output (override with `.groups` argument)| network_name | count |
|---|---|
| Durango | 187 |
| Guadalajara | 44 |
| Mexicali | 28 |
| Tijuana | 8 |
| Xalapa | 6 |
| Piedras Negras | 5 |